GANは画像処理分野でセンセーショナルな話題を巻き起こした技術です。例えば馬をシマウマにしたり、色々な人の顔画像を作ったりすることが事が行えるようになります。画像処理界を相当ザワつかせた技術を今回は解説いたします。(どれくらい話題になったかはこちらをみると解ると思います)
GANは比較的難しい概念&技術です。表面的な解説は他のWEBサイトやQiitaなどでも取り上げられています。今回はオリジナルの論文から数式やアルゴリズムにどういう意味があるのかということについて解説し、最後にPyTorchによる実装例を紹介します。
GANとは
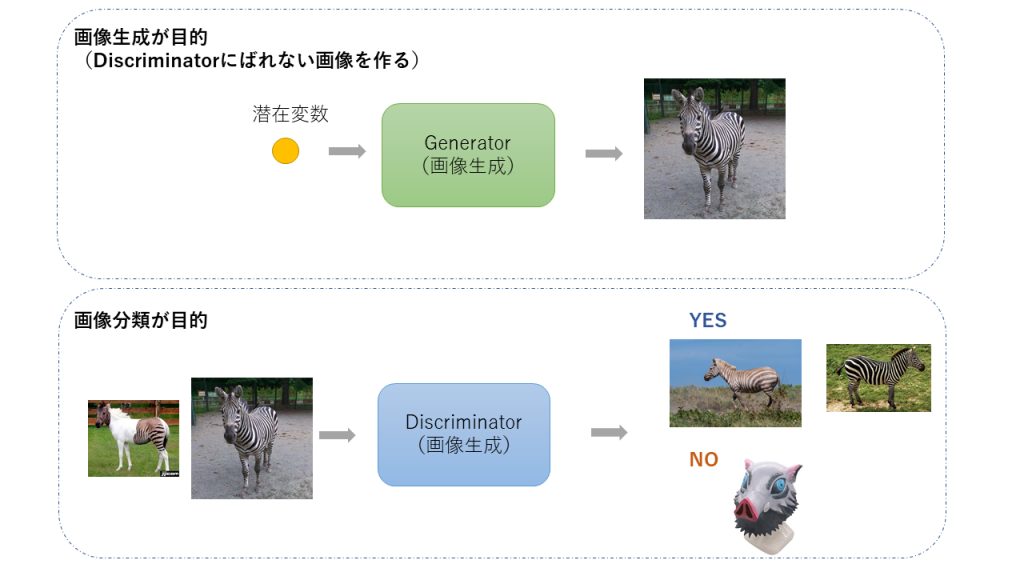
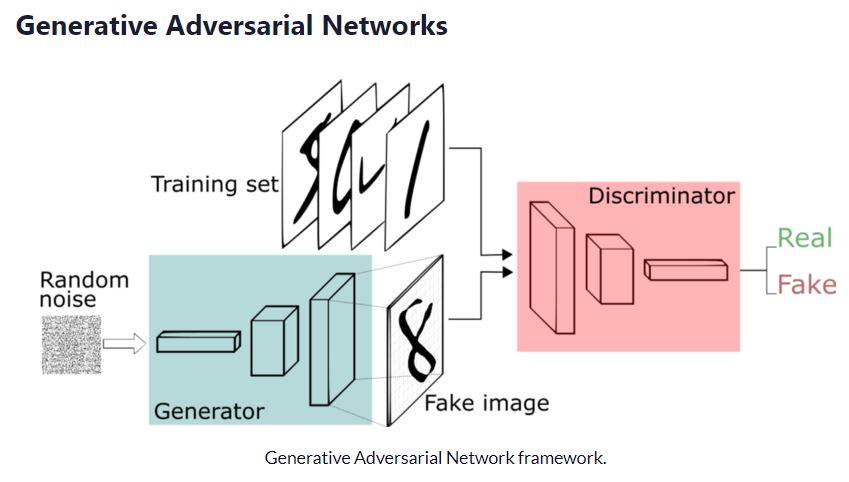
GANには2つのモジュールGenerator(生成者)、Discriminator(識別者)のがあります。これをニューラルネットワークで作っていくのです。説明のために画像処理の技術として話を進めていきます。Generatorは画像を作る、Discriminatorは画像を識別する技術を表します。
例えばシマウマ画像をGeneratorは作る、Discrimanatorは本物のシマウマの画像かを識別する器を作っていきます。
GANは Generative Adversarial Nets の略ですが、 Generative (生成する)、 Adversarial (敵対者)という言葉が入っています。これは、互いに騙し合うモデルを作る、というコンセプトから来ています。絶対に騙そうとする者と絶対に判別してやる者という、いわば矛と盾のようなものを学習により作っていくのです。GANはGANsと表現する事がありますが、これは語尾がNetsとなっているからであり、どちらも変わりません。

矛、騙す側はGeneratorと呼ばれます。後述しますが、学習が進むにつれて相手を騙すほどの画像が作れるようになるのです。GANの目的は素晴らしいGenereatorを作ることです。
盾、判別側はDiscriminatorと呼ばれます。日本語では判別器、識別機などとも呼ばれています。こちらは最終的に本物か偽物かを判断します。実装での出力値は確率で出てきますが、一番最後の最後にシグモイド関数をかませて0か1か(正か偽か)を出力します。
GANはこうしたGenerator & Discriminatorというコンセプトを用いた学習方法です。今様々なGANがありますが、なぜ沢山あるのかと言えば、 目的や実装方法によって名前が変えるためです。したがって DCGAN, LAPGAN , SRGAN, StackGAN なども全ては広くGANの一種、というような言い方が可能です。 GeneratorとDiscriminator というコンセプトを使って学習していくモデルがGANということなのです。
察しのいい人は気づいたかもしれませんが、盾であるDiscriminatorの学習はGeneratorよりもずっと簡単です。ラベル付き画像の学習であり伝統的なNNそのものとなります。
GANの目的はGeneratorを作ることです。それを忘れないようにしましょう。学習したGeneratorを使うことで人間も騙せる画像を作っていけるのです。
GANの学習の流れ
Generator
Generatorは適当な入力値をランダム値でもらい、ターゲットとなる画像を生成します。100次元程度のランダムな値が入力値として良く利用されます。生成した画像をDiscriminatorに渡し、正か偽かを判定してもらいます。Discriminatorの判定結果を受け、騙せたか騙せていないかの2値からバイナリクロスエントロピーによりロスを計算し誤差伝搬をして、Generator内部のネットワークの重みを更新していきます。
- ランダムノイズを作成する
- ランダムノイズから画像を作成する
- Discriminatorから真か偽かの判定をもらう
- Discriminatorからの判定をもとにロスを計算する
- Discriminator&Generatorを通して更新すべき重みの値を受け取る
- Generatorのみネットワークの重みを更新する
Discriminator
Discriminatorは、Generatorが出力した偽画像と、予め用意してある本物の画像を次々と入力して学習します。最終的にはシグモイド関数を利用してTrue もしくはFalseを判定結果として出力し、正解画像、偽画像が正しく識別できたかどうかを比較します。出力値は2値なのでGenerator同様にloss関数としてbinary cross-entropyを利用して精度をあげていきます。流れとしては次のとおりです。
- 本物の画像とGeneratorが作成した偽画像を仕分ける
- 真画像を偽と判定した、あるいは偽画像を真と判定したロスを計算し、ペナルティを与える
- ネットワークの重みを更新する。
Note(注意)
Discriminatorの学習は簡単です。Generatorから偽画像を生成してもらって、それと正解画像を入力して正答率を上げるだけですので、見てみればよくある典型的なニューラルネットです。
Generatorの学習でユニークなところはDiscriminatorを噛ませて出力しているところです。GeneratorはDiscriminatorの出力値を見ながら、騙せるような画像を作っていくのです。Generatorの学習注意上で重要なのは、誤差伝搬(Back propagation)の際にはDiscriminatorの重みは更新しないようにする事です。ただし、学習時には連結しているのでGeneratorへの重み伝搬の際にはDiscriminator内部も通っていくことになります。
学習はDiscriminatorとGeneratorをループでぶん回して学習していくことになります。エポック数と言われるものが、全体のループを決めるものとなります。
最初Generatorは全然学習できていないのでノイズっぽいデータが出てくることになるでしょう。Discriminatorも判定が出来ないので全く判別できないはずです。エポック数が多くになるにつれて判別ができるようになってきます。
オリジナルの論文で言及していますが、Generatorの学習は十分なDiscriminatorの学習が出来ないのであればしないほうが良いということを行っています。the Helvetica scenarioを避けるためというような、つまらないイギリシアンジョークをいれていますが、要するにDiscriminatorの学習精度を上げるためGeneratorよりも多く学習することが大事です。
さて、今までの説明をもとに疑似コードを見て全体像を掴んでみましょう。
擬似コード
# 200回Generatorを学習
for epoch in range( 200 ):
for j in range( 20 ): # Discriminator。Generatorよりも多く学習する。
# 偽画像をGから生成する。最初はそれこそランダムっぽい画像が出るが、学習に従って段々と精度が上がる
fake_images = G.generate_images()
# 本物の画像を取得。
true_images = get_correct_images()
# 偽物の画像を取り出していき学習
for f_img in fake_images:
# False or True(0,1)で結果が帰ってくる。
answer = D.check( f_img )
# 偽画像と判定するべきなので、正解であるFalseを教えて重みを更新
D.update( answer, False )
# 本物の画像をとりだしていく(上記と同じ事を正解画像でやる)
for t_img in true_images:
answer = D.check( t_img )
D.update( answer, True ) #正解画像なのでTrueを渡す。
# ----------------
# Discriminatorの学習が終わったので、Generatorの学習をする。
# ----------------
# UpdateされたDを用いて学習する
G.set_discriminator( D )
# 画像を生成するためのシードを作ってやる
random_images = get_random_image()
# シードから画像を取り出す
for r_img in random_images:
# G.check内ではFake画像を生成し、Dに判別させ、結果を得る作業が入っている
answer = G.check( r_img )
# 得た結果からGの重みを更新。なお、この際にセットしたDの重みは更新しない。
G.update( answer )
上記は実装よりの疑似コードですが、概要を知るためにじっくりと眺めてください。そして、上記を見ないで自分で擬似コードを書いてみましょう。
機械学習で最も大事なのはコンセプトの理解です。第三者が書いたコードを写経やコピペしてすぐに走らせたくなる気持ちはわかりますが、こうした一見複雑な仕組みの理解には自分で疑似コードを書くことがおすすめです。他の人のソースコードのコピペでは理解することは難しいでしょう。
GANの数式
GANでは次の式が利用されています。
\underset{G}{\text{min}} \underset{D}{\text{max}}V(D,G) = \mathbb{E}_{x\sim p_{data}(x)}\big[logD(x)\big] + \mathbb{E}_{z\sim p_{z}(z)}\big[log(1-D(G(z)))\big]一見摩訶不思議ですが、実は非常に簡単です。Gは最小化になるように、Dは値が最大になるようにしたいという意味が込められています
G(z)はFake画像です。zという潜在変数をGという関数にいれて画像を生成することを意味しています。さらにそれをDiscriminatorの関数に噛ませたものがD( G( z ) )と表現されます。
Generatorにとってみると、D(G(z))が1になる、つまり本物と誤解するようにしたい、という意味です。
Discriminatorにとっては左辺は無視します。log( D(x) )は本物のデータを用いる、当然1になるためです。右辺に注目して、log( 1 – D( G(x) ) )において、 D( G(x) )が0になるように頑張るのです。
Generatorにとっては最小化、Discrimanatorにとっては最大化する、というのはこのためです。
EはExpected Lossなのですが、添字のx〜pdata(x)とは確率分布pdataからxを独立的にサンプリングするという意味になります。Eは期待値ですので、イメージ的には全てを足し合わせてサンプル数で割った値となります。例えば200人の人の身長の高さの期待値は次のようになります。
{\Bbb E}[h]=(\sum_{n=1}^{200}h_n)/200pdata(x) の範囲からxとしてサンプリングしていき、適用して、期待値として最大化する(最小化する)というような意味が込められています。
このような数式の表現の方法、ルール、解説についてhttps://www.hellocybernetics.tech/entry/2018/07/16/234815 に詳しく書いてあります。わからない方は読んでみてください。
PyTorchに依る実装
Pytorchによる実装を示します。PyTorchはプリファード社(Chainerを作っていた会社)が推奨した後継のライブラリです。kerasもいいですが、私は PyTorchのほうがPythonライクで好きです。
まずは画像の取得関数を定義します。
画像取得関数
# 画像取り出し。
import os
from torchvision import datasets
import torchvision.transforms as transforms
def get_dataloader():
location = "data/mnist"
os.makedirs(location, exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
location,
train=True,
download=True,
transform=transforms.Compose(
[ transforms.Resize( 28 ), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=64,
shuffle=True,
)
return dataloader
単に画像をdata/mnistに保存すると言うだけの画像取得ローダーです。今回は本質にかかわらないので詳しくは説明しません。ただ、今後自分で何か学習用の画像を手に入れた際はローダーを自分で定義していくことになるので、どこかで使い方をマスターする必要があります。
続いて、GeneratorとDiscriminatorのクラスを定義します。最初はGeneratorクラスです。
Generatorクラス
import torch.nn as nn
class Generator( nn.Module ):
def __init__( self, z_dim = 100, channel = 1, w = 28, h = 28 ):
super().__init__()
self.latent_dim = z_dim
self.img_channels = channel
self.img_width = w
self.img_height = h
self.img_shape = ( self.img_channels, self.img_width, self.img_height )
def _block( in_feat, out_feat, normalize ):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append( nn.BatchNorm1d( out_feat ) )
layers.append( nn.LeakyReLU( 0.2 ) )
return layers
self.model = nn.Sequential(
*_block( self.latent_dim, 128, normalize=False ),
*_block( 128, 256, normalize=True ),
*_block( 256, 512, normalize=True ),
*_block( 512, 1024, normalize=True ),
nn.Linear( 1024, int( np.prod( self.img_shape ) ) ),
nn.Tanh()
)
def forward( self, z ):
img = self.model( z )
img = img.view( img.size( 0 ), self.img_channels, self.img_width, self.img_height )
return img
初期化関数__init__内部ではmodelを作成していきます。Generatorは潜在変数zを受け取って疑似画像を作成しますので、潜在変数zの次元数を受け取れるように設定しています。
nn.Sequentialの内部を見るとわかりますが、まずは100次元を受取、128次元に、128次元からノーマライズして…と繰り返し1024次元に変更した後、にnp.prodを用いいて画像の最終的な次元に展開しています。normalized処理がないと値が安定しないので必ず入れるようにします。
np.prodというのは要素内の全てを掛け合わせるという意味です。img.size( 0 )はバッチ数を意味していて、最初に説明したdata-loaderの設定にもよるのですが64を返します。 ミニバッチ数とは、例えば入力を1枚1枚でなく、64枚の画像単位(バッチ単位)で学習するという意味です。
続いてDiscriminatorの実装例を表示します。
Discriminatorクラス
class Discriminator( nn.Module ):
def __init__(self, channel = 1, w = 28, h = 28):
super().__init__()
self.img_channels = channel
self.img_width = w
self.img_height = h
self.img_shape = ( self.img_channels, self.img_width, self.img_height )
self.model = nn.Sequential(
nn.Linear( int( np.prod( self.img_shape ) ), 512),
nn.LeakyReLU( 0.2 ),
nn.Linear( 512, 256 ),
nn.LeakyReLU( 0.2 ),
nn.Linear( 256, 1 ),
nn.Sigmoid(),
)
def forward( self, img ):
img_flat = img.view( img.size( 0 ), -1 )
validity = self.model( img_flat )
return validity
Generator同様にimg_shapeは画像のチェネル数(RGBなら3チャンネル、グレースケールなら1チャンネル)、画像縦、画像横サイズを保持しています。こいつをnp.prodすることにより、例えば3チャンネル16×16の画像なら768次元に全て展開されます。その次元をだんだんと落とし込んでいき、最後には1次元にしてSigmoid関数に噛ませていきます。
Discriminatorは本物かどうかをYes/Noで判定する学習機でした。そのため、次元を少なくしていきます。最後にシグモイド関数をいれて強制的に0か1にします。シグモイド関数をいれない直前に関しては確率密度関数といわれます。(ここでは割愛)
さて、forward関数ではimg.size( 0 )でミニバッチ数をとりだし、-1を渡して自動展開しています。それをモデルに突っ込んで0か1を受け取っています。
これで準備は整いました。それでは学習プログラムをつくります。メインのプログラムを下に記します。
メイン関数
import torch
def main()
batch_size = 64
# 色々と初期化
Tensor = torch.cuda.FloatTensor # Tensor = torch.FloatTensor
generator = Generator().cuda()
optimizer_G = torch.optim.Adam( generator.parameters(), lr=0.0002, betas=( 0.5, 0.999 ) )
discriminator = Discriminator().cuda()
optimizer_D = torch.optim.Adam( discriminator.parameters(), lr=0.0002, betas=( 0.5, 0.999 ) )
# ロス関数の初期化
adversarial_loss = torch.nn.BCELoss().cuda()
epoch_size = 200 # 普通は100-200くらい。
for epoch in range( epoch_size ):
dataloader = get_dataloader()
for i, ( real_images, some ) in enumerate( dataloader ):
batch_size = real_images.size( 0 )
# 正解と不正解のラベルを作る
valid = torch.ones( (batch_size,1), requires_grad=False ).cuda()
fake = torch.zeros( (batch_size,1), requires_grad=False ).cuda()
# ---------------------
# Dの学習
# ---------------------
# DはGより20回多く学習をさせる。( オリジナルの論文より)
for j in range( 20 ):
# まず初期化
optimizer_D.zero_grad()
# 偽画像の作成
# ランダムな潜在変数を作成
z = torch.empty( real_images.shape[0], 100,requires_grad=False ).normal_( mean = 0, std = 1 ).cuda()
# fake imageを取得
fake_images = generator( z )
# ロスの計算.
real_loss = adversarial_loss( discriminator( real_images.type( Tensor ) ), valid )
fake_loss = adversarial_loss( discriminator( fake_images.detach() ), fake )
d_loss = (real_loss + fake_loss) / 2
# 勾配を計算
d_loss.backward()
# 伝搬処理。Dにだけ誤差伝搬される
optimizer_D.step()
# ---------------------
# Gの学習
# ---------------------
# まず初期化
optimizer_G.zero_grad()
# ランダムな潜在変数を作成
z = torch.empty( real_images.shape[0], 100,requires_grad=False ).normal_( mean = 0, std = 1 ).cuda()
# fake imageを取得
fake_images = generator( z )
# discriminatorを利用して結果を取得する
g_loss = adversarial_loss(discriminator( fake_images ), valid )
# 勾配を計算
g_loss.backward()
# 重みを更新する。Gのみにだけ勾配伝搬処理がされる
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, epoch_size, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % 400 == 0:
save_image(fake_images.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
optimizerはそれぞれ、Discriminator とGeneratorで設定します。
ロス関数はバイナリ値(0もしくは1)なのでその関数をセットします。
Valid, Fakeは単に正解ラベルとして差分を計算するために出力しているだけです。
Pseudo-codeで記載したとおりまずはDの学習を先行します。Discriminatorの学習率をアップしたほうが学習結果が良いためです。
Generatorが吐き出した学習結果は次のとおりとなりました。

段々と精度が上がってきているかわかります。見ていると、どうも7,9,1が多いです。こうした減少はよく知られている現象(モード崩壊)で、それを避けるためのテクニックも随所論文で見られます。
ソースコード
https://github.com/octopt/techblog/blob/master/gan/main.py
Githubに上げておりますので参考にしてください。
最後に
GANを作っていくと、学習していくと面白いことに気づきます。例えばGeneratorはよく出来た文字を作り出します。人間でも間違うくらいです。というよりは間違えます。あたかも人間が間違えた文字を拒否する構造は正しいのでしょうか?たしかにそれはGeneratorが作ったものですが、人間が作ったものと同じかもしれません。こうしたことにはどう対処していくべきでしょうか?こんなことも考えながら色々と工夫をしていくと面白いと思います。
手書き文字ではかなりシンプルでした。人間の顔などで作っていくとまた面白い結果が出るでしょう。
参考文献
- https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf
- https://towardsdatascience.com/understanding-generative-adversarial-networks-gans-cd6e4651a29
- https://medium.com/deeper-learning/glossary-of-deep-learning-batch-normalisation-8266dcd2fa82
- https://github.com/eriklindernoren/PyTorch-GAN
全体の流れがとてもよくわかりました。
ありがとうございます!とても嬉しいです。なにかご不明端点がりましたらいつでも投稿ください!