はじめに
音声データや、文章データなどの時系列データの学習には再起型ニューラルネットワークと呼ばれるRNN(Recurrent Neural Network)が用いられます。
2012年頃、Google社の翻訳機能が劇的に改善された事は記憶に新しいです。この技術のベースはLSTMという技術でありましたが、LSTMはRNNの一種となります。蛇足ですが翻訳エンジンはLSTMを少し工夫しEncoder&Decoderという概念を持ち込んで高精度の翻訳機を完成させたのでした。
本稿ではLSTMのベースとなるRNNについて説明していきます。RNNの活性化関数を工夫したものがLSTMであり、RNNさえ理解できればLSTMも理解ができます。
再起型ニューラルネットワーク(RNN)とは
「再帰」という表現がついていますが、従来のニューラルネットワーク(NN)との違いは、隠れ層の出力データの取り扱い方です。ニューラルネットワークでは隠れ層を横に増やしていき、複雑な学習を行おうとすると横長に広がっていくイメージでした。
一方でRNNは従来のNNとは異なり、1つ前の隠れ層の出力を入力として利用します。そのため、イメージ的には将棋倒しのように答えが出てくる形となります。
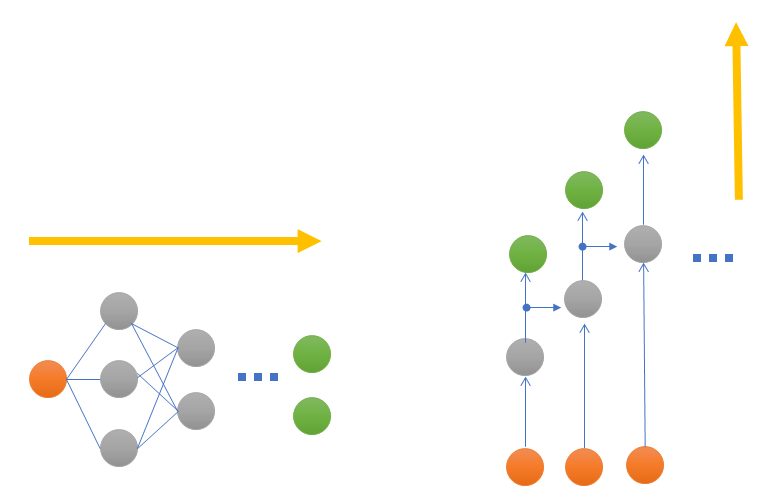
RNNを用いたアプリケーション
翻訳エンジンにあっ使われている他、文字推薦や自動文章作成などが具体的な実装事例です。
文字推薦とは携帯電話でのメールなどでおなじみですが「app」と入力したときに本当に入力したい単語 apple, application などを教えてくれる機能です。
文章作成でも[ the dog eats ] と書くと「dog-food」や「my-homework」等の単語の候補を出す技術にRNNがよく利用されています。RNNは前段の隠れ層の出力を使うという特性から連続性のあるものの扱いが上手く表現できると考えられています。
RNNの構造
RNNの構造はシンプルです。入力データと前段の出力結果(隠れ層の出力)を足し込み、活性化関数にかませて結果を出します。出力結果の値は次段におくります。先程も述べたとおり、この出力結果を次段に送るというのがRNNがシーケンシャルなデータを扱えると考えている理由となります。
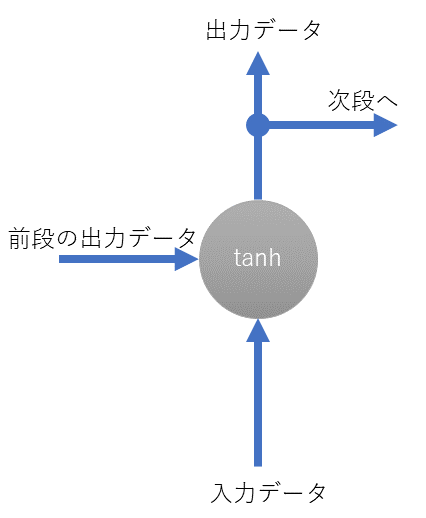
入力データと前段のデータを用いて出力するための関数である活性化関数は、tanhが利用されます。
先程は説明のために端折りましたが、活性化関数tanhにかませるデータは重みを加味して足し込みます。NNと同様にこの重みが肝であり、重み更新処理がRNNでも目的となります。
ちなみになぜtanhが活性化関数として利用されるかというと、勾配を保つために、2次導関数が長い範囲にわたってゼロにならない状態を持続する必要があるのですが、tanhはこれに適していたからです。
実際のRNNの素子の構造
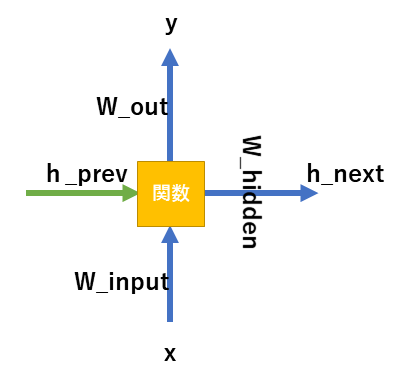
具体的には次のような数式を用いて、出力層、中間層(隠れ層)の値を求めます。
隠れ層(中間層の出力)
h_{value} = tanh( h_{prev}+w_{input} * x )出力層
y =softmax( w_{out} * h_{value} )中間層の入力
h_{next} =w_{hidden} * h_{value}h_nextは次段でh_prevとして扱われます。下図を参考にしてください。
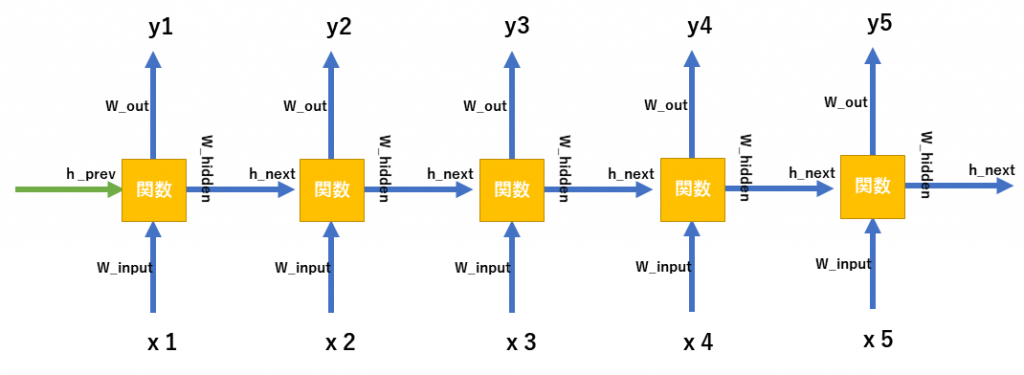
実際の計算の概略
tanhで計算すると説明いたしましたが、実際にはベクトルデータに対してどうやって計算を適用するのか疑問に思うかもしれません。実際のベクトルやマトリックスを使った演算例を下に記載します。
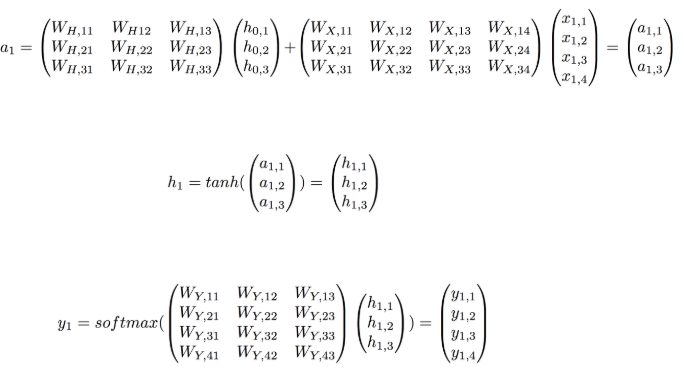
x1..が入力データh0…が前段からくるデータ。h1…が今回新しく作られた隠れ層の出力。上記はよく見ていくと分かると思います。
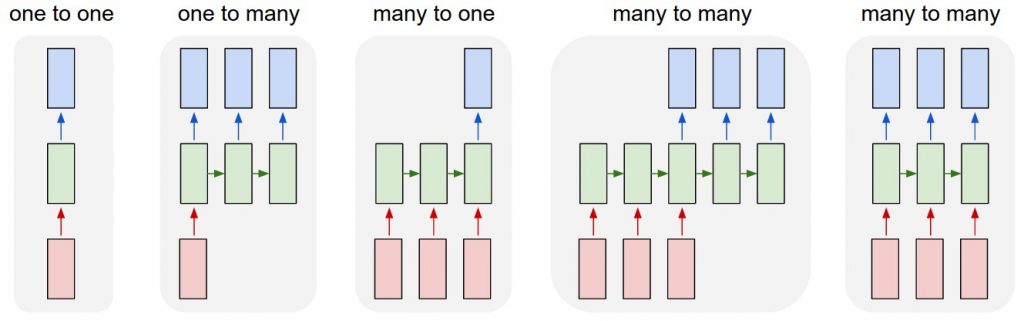
RNNの出力結果の取り扱い
RNNの面白いところの一つとして、値の扱われ方があります。例えば前の図で言うところのYの出力ですがy1からy5まで結果を出力しました。学習モデルに応じて、全てのy1からy5の値を参考にしたり、場合によっては最後の後段の結果y5のみを利用する場合などがあります。下図がよく利用されるRNNの値の利用のされ方です。
学習データの作り方
学習データの作り方で、例えば単語推薦を実装したい場合ですが、one-hot encodingの処理がよく利用されます。(one-hot encodingに関してはword2vecを参考にしてください)
さて、appleを例にどのように入力データを扱うのか下図のとおりとなります。
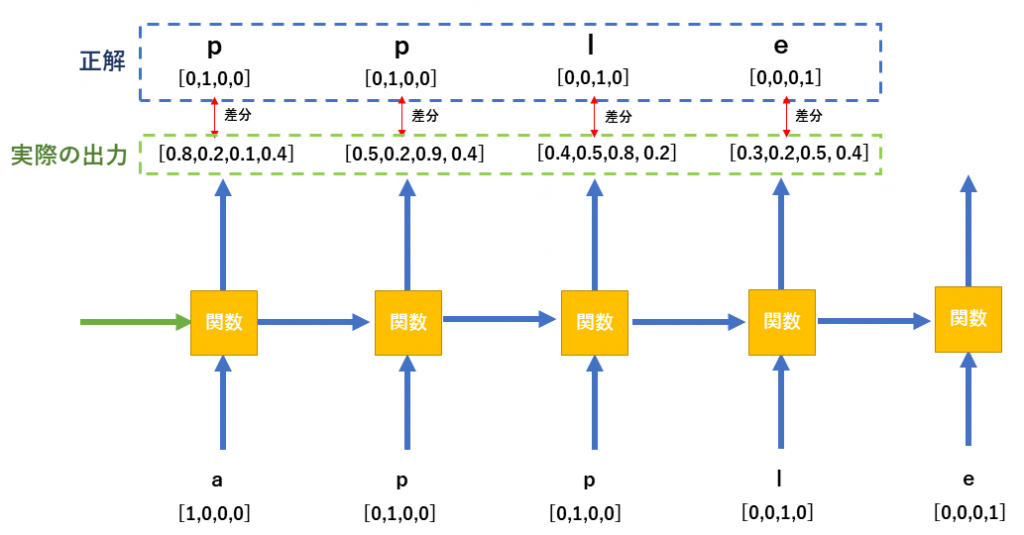
出力結果と、正解値を比較し差分を求めて、重みを更新していく処理となります。重み更新にはBPTTという方法で行われます。
Back propagation through time ( BPTT )
RNNは従来のNNとは違い時系列になっている(前段のデータを利用している)ため、少し工夫が必要になってきます。
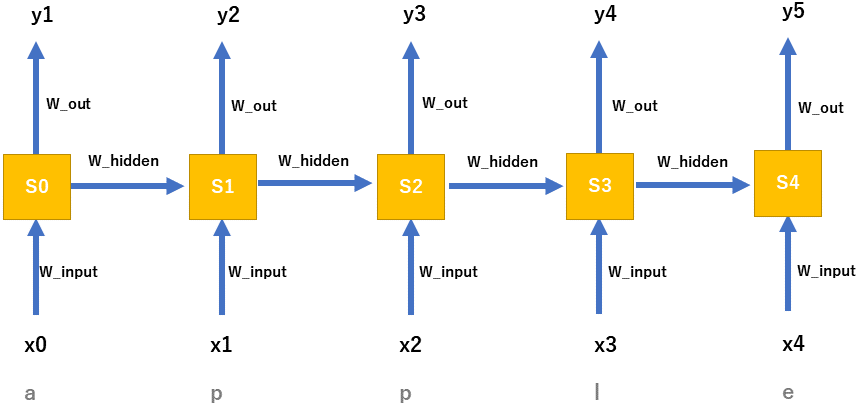
バックプロパゲーションは、最終的な結果との誤差を、重みベクトルに反映させていく処理となります。更新する重みは全部で3つありました。 w_{out} , w_{hidden} , w_{input} の3つです。
誤差を計算するためのロス関数としてはマルチクラスエントロピーロス関数を利用します。
L( y, \hat{y} ) = -y log( \hat{y} )w_inputへの誤差(E_w_input)
導出の過程を記載すると長くなるので、結論だけ書きます。
E_w_input = d3x3+d2x2+d1x1+d0⋅x0
w_hiddenへの誤差 E_w_hidden
まずd3, d2, d1, d0は次のように定義します。。
d3 = (\hat{y3}−y3)⋅w_{out}⋅(1−s3^2) d2 = d3⋅w_{out}⋅(1−s2^2) d1 = d2⋅w_{out}⋅(1−s1^2) d0 = d1⋅w_{out}⋅(1−s0^2)求めたd0-d4を用いいて、差分を計算します。こちらも導出を書くと長くなるので結論を記載します。
E w_{hidden}= d3 s2+d2 s1+d1 s0+d0⋅s−1w_inputへの誤差 E_w_input
Ew_{input}= (\hat{y3}−y3) s3補足
詳しい導出過程については参考文献を参考にしてください。[1]
最後に
RNNの詳しい実装方法について記載しました。LSTMは実は活性関数に工夫を入れるだけとなります。
参考文献
[1]https://songhuiming.github.io/pages/2017/08/20/build-recurrent-neural-network-from-scratch/