回帰分析の概念はとても簡単です。データにフィッティングする直線を見つけるという事だけです。例えば、身長と体重の相関関係を知りたいとします。直感的にですが、身長が高くになるに連れて、体重も増えそうですね。
体重 = a * 身長
となるような直線を推定する、これが回帰分析です。ここでよく見ると、y = a * xという式と同じです。( yが体重、xが身長)。つまり、回帰分析は傾きaを求めるための分析方法ということです。
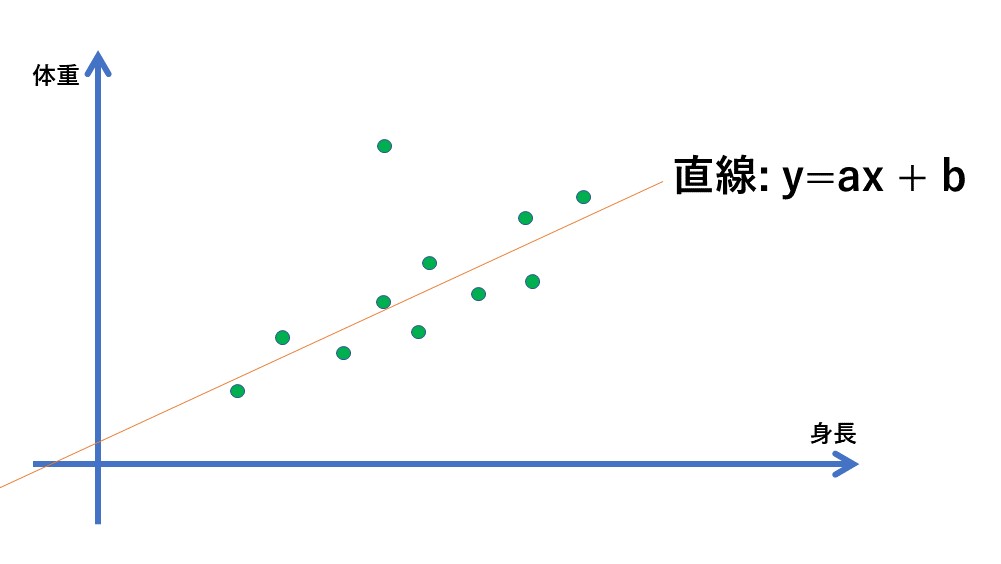
さて、今の回帰分析は単回帰と呼ばれています。もっと複雑に体重を求めたいかもしれません。例えば説明変数「性別、宗教、胸囲、頭の多さ、身長」から、「体重」を求める、というものです。このように複数の説明変数から、体重を求めたい場合(説明変数の傾きを求めたい場合)は重回帰分析と呼ばれています。式は次のような形となります。
y = a_1x_1 + a_2x_2 + a_3x_3 + ...説明の通り複数の説明変数がある場合が、重回帰分析と呼ばれています。重回帰分析でどうやって係数群をもとめるかは最小二乗法のコラムをご覧ください。
少し話はそれますが先程上げた「性別、宗教、胸囲、頭の多さ、身長」から「体重」を求めるという行為は実はやってはいけません。コンプライアンス的にという意味ではなく、重回帰分析のルールとして次のがあるためです。重回帰分析には次のルールがあります。
- 説明変数は独立であること。
- 説明変数は連続値であること。
身長と、胸囲は相関関係があり独立ではありませんね。身長が高くなると胸囲があがるという相関関係がありそうです。また、性別は0か1ですので連続値ではありません。宗教もイスラム、キリスト、仏教、神など連続ではないです。
なお、ルールを無視しても精度は出ます。ただ適切ではないです。論文などの公式なところに使えば突っ込まれるだけで、社内のデータなどでは使っても問題はありません。それでは、多変量解析のデータを解析する上でどういう方法を使えばいいかについて、迷った場合は以下を参照ください。
| 従属変数 | 従属変数が量的 | 独立変数が量的 | 使用できる多変量解析の種類 |
| あり | YES | YES | 重回帰分析 |
| あり | YES | NO(質的) | 分散分析、多重分類分析、数量化理論Ⅰ類 |
| あり | NO | YES | 重回帰分析、判別分析、ロジスティック回帰分析 |
| あり | NO | NO(質的) | 対数線形モデル、数量化理論Ⅱ類 |
| なし | – | YES | 因子分析、主成分分析 |
| なし | – | NO(質的) | クラスター分析、多次元尺度法、数量化理論Ⅲ類 |
従属変数とは、y=a_1x_1 a_2x_2でいうところの、yが存在するかどうかを表します。質的なデータとは0,1で区別されるようなデータ、量的とは連続なデータか、0〜1の範囲でくまなく分布する連続するデータか、という意味を示します。
例えば、宗教(質的)と性別(質的)から癌になる確率(量的)を求めたい場合は数量化理論Ⅰ類を用いることとなります。
さて、重回帰分析では、一個の従属変数と複数個の独立変数の線形合成変数の相関が最大となるような重みを求めることを目的としています。(従属変数y、独立変数x、重みa)説明変数が一つなら単回帰分析。2つ以上なら重回帰分析となり、単回帰分析とは直線近似を指し、重回帰分析はそれの一般化で超平面を指します。
今、目的変数yに対し、説明変数xがどれだけの重みを持っているのかということを求めるのが重回帰、単回帰分析であると説明しましたが、改めて式にして表せば、
(単回帰分析) Y=aX
(重回帰分析) Y=aX // 太字になっているということで、ベクトルを表している。
終わりに
目的変数がひとつであることが回帰分析であると説明しました。重回帰分析は単回帰分析の一般化です。重回帰分析を更に一般化すると、正準相関分析となります。正準相関分析については、また別途解説いたします。
参考文献
https://ja.wikipedia.org/wiki/%E5%9B%9E%E5%B8%B0%E5%88%86%E6%9E%90
おすすめの記事
- 数量化理論Ⅳ類(MDS)
- 正準相関分析(Canonical Correlation)
- 特異値分解(SVD)
- 主成分分析(PCA)
- 線形判別分析(LDA)
- 単純ベイズ分類器(Naive Bayes Classifier )
- 最小二乗法による重回帰分析