はじめに
Word2Vecは近年で最も注目された技術の一つです。主にNLP( Natural Language Processing:自然言語処理 )の分野の技術なのですが、広告や商品ページなどの推薦エンジン技術として利用されています。実際に楽天などでは本技術を使っているようです[1]。
コンセプトはとてもシンプルです。今回はWord2Vecがどういう技術かをpythonをもとにnumpyを使ったソースコードの実装例をもとに説明します。(gensimなどのライブラリは使いません!)。実際内部でどのような処理が行われているか参考にしてください。
どのようなモデルか
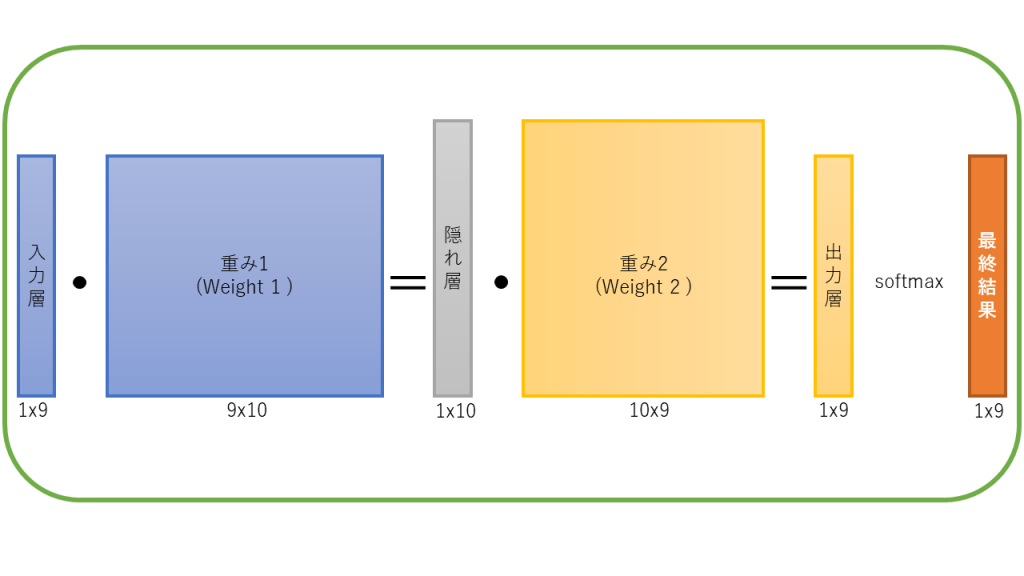
このような構成をしています。すべて本ブログで解説しますので、読み終わる頃にはよくわかります。
Word2Vecは何か
単語をベクトル化する、これをWord2Vecが行います。単語のベクトル化ができることで、四則演算が使えてしまうのです。。
例えば、仮に単語の「神様」:[5, 1, 3]というベクトルで表した場合、「神様」と似ているベクトルを探すこと(例えばコサイン積をとって1に近いものを探すこと)ができます。他にも「神様」:[5,1,3]へ新しく、例えば「海」:[1,2,3]というベクトルを足し込んだ結果を探すと、「リヴァイアサン」:[6,3,6]がヒットするかもしれません。外積をとって直行する言葉を探すなんてこともできそうですね。
その昔、類似度を探す技術と言えば共起行列を用いて探る方法が一般的でした。文章から単語を抽出してともに出現する単語から共起行列を作成してSVDなどで解析し、特徴量空間にマッピングして類似度を算出するのです。ただ、この方法では行列のサイズが大きくなると計算がおいつかなくなる問題がありました。2013年にGoogleの研究者がWord2Vecを提案し、業界がざわつきました。
単語をベクトル化することは「word embedding」と呼ばれます。
Word2Vecの実装に向けて
Word2Vecのアルゴリズムは大きく2つあり、違いは次のとおりです。
- Continuous Bag-Of-Words (CBOW)
- Skip-gramよりも数倍学習が早く、頻出単語に関しては若干の高い精度を誇っている。
- Continuous Skip-gram (SG)
- 小さい学習データから珍しい単語やフレーズを上手に表現できる。
2つともに近くの単語( context words )からの確率分布を用いた手法であります。近傍の単語から新しい単語の類推をしていきます。今回はSG( Skip-gram )を説明します。
学習方法
学習データは文章を使います。今回は次のフレーズを元にWord2Vecを説明します。
「Although the world is full of suffering, it is full of the overcoming of it.」
(世界は苦しいことでいっぱいだけれども、それに打ち勝つことでもあふれている。) : マザーテレサ
上記英語フレーズを学習データとします。実践では長い文章を用意します。
さて、Skip-gram では学習にニューラルネットワークを使います。教師データとなるトレーニングデータは単語の近傍の単語(context wordsとよばれる)です。具体的に行きましょう。例えば、先のフレーズの「world」であれば、[Although, the, is, full]がcontext wordsとして学習セットになります。

フレーズ内の、すべての単語に対し同様に学習セットを用意します。たとえば、Althoughの近傍の単語context wordsは[the, world]となります。後述しますがovercomingの近傍ワードは[ of,the, of, it ]ですが、重複は除かれるルールになるので [ of,the, it ] となります。
Vocabulary & One-hot Encoding
Vocabulary
具体的な学習データの作り方ですがVocabulary(ボキャブラリ)を構築し、one-hotエンコーディングを実施する必要があります。
「Vocabulary」とは重複のない単語群のデータです。まずは文章を空白区切りします。
[‘Although’, ‘the’, ‘world’, ‘is’, ‘full’, ‘of’, ‘suffering,’, ‘it’, ‘is’, ‘full’, ‘of’, ‘the’, ‘overcoming’, ‘of’, ‘it’]
そして、重複を除きます。
[‘Although’, ‘the’, ‘world’, ‘is’, ‘full’, ‘of’, ‘suffering,’, ‘it’, ‘overcoming’]
‘it’, ‘is’ , ‘full’ , ‘of’ , ‘the’の重複が取り除かれ1つになり、9次元のデータがとれました。これで「Vocabulary」 が完成しました。
One-hot encoding( One hot vector )
続いてone-hotエンコーディングを行います。図を見るとわかりますが、単純に単語があるところを1にし、それ以外を0にするだけのベクトルを作るという意味です。

One-hot vectorとも呼ばれています。さて、以上で下準備は終わりました。
最初にworldのcontext wordsは「Although, the, is, full」と説明しました。このデータはone-hotベクトルで表現すると [list([0,0,1,0,0,0,0,0,0]), list( [ 1,0,0,0,0,0,0,0,0 ], [ 0,1,0,0,0,0,0,0,0 ], [ 0,0,0,1,0,0,0,0,0 ], [ 0,0,0,0,1,0,0,0,0 ] ) ]というペアになります。
Training
学習の流れですが、学習の全体像は次のとおりとなります。
Word2Vecでは、ニューラルネットによる学習において、上記のうち、2つの重みマトリックス(W1, W2)を更新していきます。(その方法は次の章で記載します。)
学習終了後ですが、使われるものは重み行列W1です。実はこれが特徴量行列となっています。例えば、”although”[ 1,0,0,0,0,0,0,0,0]があったとして、これと学習後の重み行列W1をかけ合わせて出てきたものが”although”の特徴量ベクトルです。実際には掛け合わせると言っても one-hotベクトル内で 1が立っている行をW1から抜き出すという操作になります。
さて、では具体的にどのようにWord2Vecでは学習されているか解説します。
Trainig – Forward pass
まず、一番最初のプロセスとして行列W1,W2はランダムな0-1の範囲で初期化をしておきます。そしてニューラルネットのforward関数としては次の関数を使うことになります。
def forward_pass(onehot_input, w1, w2):
h = np.dot(w1.T, onehot_input)
u = np.dot(w2.T, h)
y = self.softmax(u)
return y, h, u
onehot_inputは先の例で言うところの [0,0,1,0,0,0,0,0,0] (入力単語 worldのone hot表現)です。重み行列W1とonehot_inputでドット積を実行してHiddenベクトルh(隠れ層)が求められます。続いて、重み行列W2とHiddenベクトルhでドット積を実行し、出力ベクトルuを算出しsoftmax関数をかけて予測値ベクトル yを算出します。
結局のところforward_pass関数におけるリターンバリューとしては[予測値ベクトル y、Hiddenベクトルh、出力層ベクトルu]の3つを得ます。 softmax関数により必ず値が0〜1の範囲になります。
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
Training- Error
forward_pass関数の結果から予測ベクトルyが返ってきました。このyベクトルの値はsoftmax関数を噛ましているので必ず0-1の範囲に収まっています。さて今、次の予測ベクトルyが返ってきたとします。
y = [0.888, 0.801, 0.766, 0.552, 0.659, 0.371, 0.517, 0.087, 0.212]
ここで、出力すべきであった 「although, the, is, full」のone-hotベクトル[ 1,0,0,0,0,0,0,0,0 ], [ 0,1,0,0,0,0,0,0,0 ], [ 0,0,0,1,0,0,0,0,0 ], [ 0,0,0,0,1,0,0,0,0 ] それぞれと 予測ベクトルyの差分を取ります。期待された結果からどれだけ間違えたかを差分として求めるのです。具体的に示します。
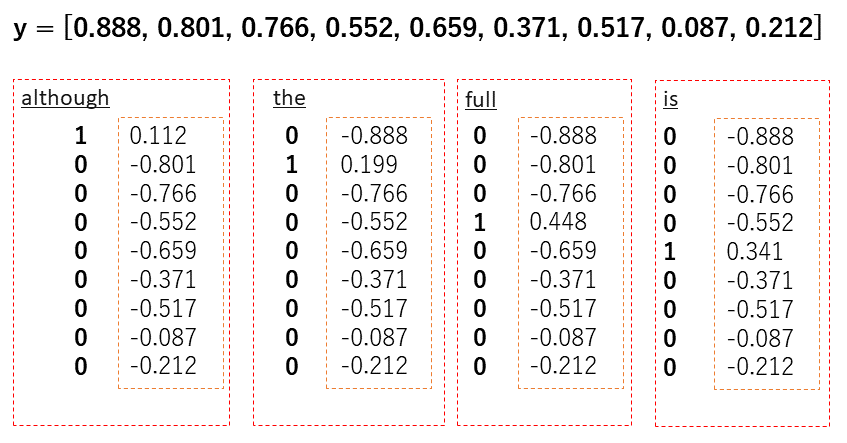
こうして出来た、それぞれの単語で求められたエラーベクトルをすべて足し込み1つのエラーベクトルをeを作ります。このエラーベクトルeはBack Propagation処理で利用し、重み行列を更新していきます。
Training- BackPropagation
ニューラルネットワークでおなじみのバックプロパゲーション(誤差逆伝播)を行います。目的はエラーベクトルeを利用して重み行列(W1, W2)を更新することにあります。
具体的な流れは次のとおりです。
- Hidden ベクトルhとErrorベクトルeで外積を取り、重み行列w2に対する差分行列dW2を作成します。
- 重み行列W2とErrorベクトルeで内積を取り、ベクトルmを作ります。入力ベクトルonehot_inputとベクトルmで外積を取り、重み行列w1に対する差分行列dW1を作成します。
それぞれの重み行列W1, W2から、 それぞれ差分行列dW1 *学習率 ,dW2 *学習率を引き、新しい重み行列を得ます。学習率は1%くらいに設定しておきます。
learning_ratio = 0.01
def backprop( w1, w2, e, h, x ):
dW2 = np.outer(h, e)
dW1 = np.outer(x, np.dot(w2, e.T))
# 重みの更新
w1 = w1 - (learning_ratio * dW1)
w2 = w2 - (learning_ratio * dW2)
以上で終わりです。これをぶん回していくことで学習していきます。学習後、W1の重み行列が特徴量行列となっています。
Trainig-Loss
損失関数を定義し、学習進み具合をチェックできます。損失関数は実際に学習作業と関係ありませんが、ぶん回す回数(エポック数)を決める上で、発散したりしていないか、きちんと収束しているかを確認する上で重要となります。
損失関数は2つの部分で構成されています。1つめは出力層のすべての要素の合計、の負の値です(softmaxの前)。 2 つめは、近傍の数であるcontext_wordsの数と、出力層のすべての要素(指数関数の後)の合計のログの乗算です。
loss += -np.sum(u) + len(context) * np.log(np.sum(np.exp(u)))
類似語の探索
特徴量ベクトルは、最初に説明したとおりone-hotベクトルと学習後の重み行列W1とのドット積によりもとまります。特徴量ベクトルを取得したら、後は、四則演算となります。例えば類似ワードは内積値が1日買い物となります。ベクトル同士の四則演算をして、得た結果かから色々と考えてみると面白いかと思います。