はじめに
Deep Learning(ディープラーニング)という言葉は、もはや殆どの人が耳にしたことがあると思います。ディープラーニングは何かを調べていくと、今いち何か掴めないという人が多いのではないでしょうか?今回はディープラーニングの1種であるCNN( Convolution Neural Networks)を中心に画像処理を例として ディープラーニングとはなにか、どう学習させていくかを説明いたします。
Deep learningの正体
ディープラーニングはDeep Neural networks(DNN)とも呼ばれており、その正体はニューラルネットワーク(NN)そのものです。ディープラーニングという言葉が流行り始めた際、中身がニューラルネットワークという事を知って、本当に驚きました。というのも、NNはとても古く伝統ある学習アルゴリズムでしたが、ランダムフォレストやSVMの台頭により、誰も利用しない、古い学習アルゴリズムとして扱われていたからです。厳密にはNNとDNNの違いは、特徴量の作成を学習化にとりいれた事でした。今まで画像処理の分野では技術者は頑張って特徴量を作り、その特徴量をNNなどの学習機で学習させていましたが、DNNでは、画像を突っ込めば前段で特徴量を勝手に作ってくれます。(厳密には特徴量を作成するフィルターを作成する。そのフィルターをかませることで特徴量マップを作成する)これは、とても斬新でした。
Forward process
さて、ディープラーニングの一種であるCNNを例にどのようなに学習しているかを説明します。CNNがわかると、DNNの構造がわかり、例えば最近の技術であるDCGANの理解も進みます。
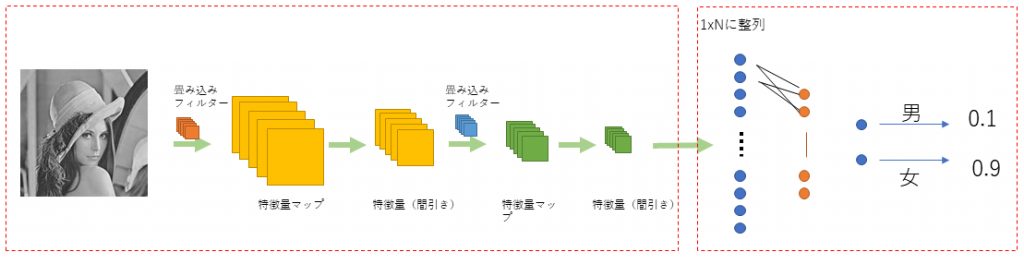
CNNはFowardプロセスとして前段と後段の2つに分けることができます。まずは前段の畳込みとプーリングについて説明します。
前段( 畳込みとプーリング )
1.畳み込み処理
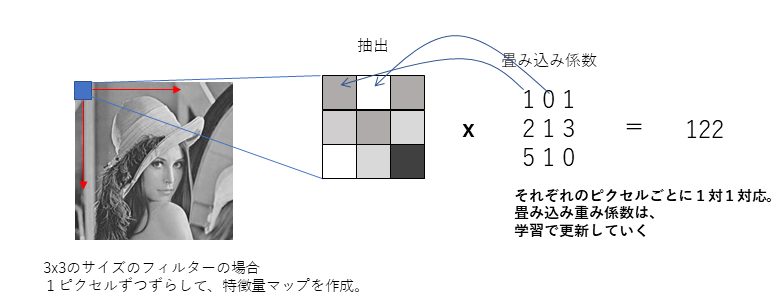
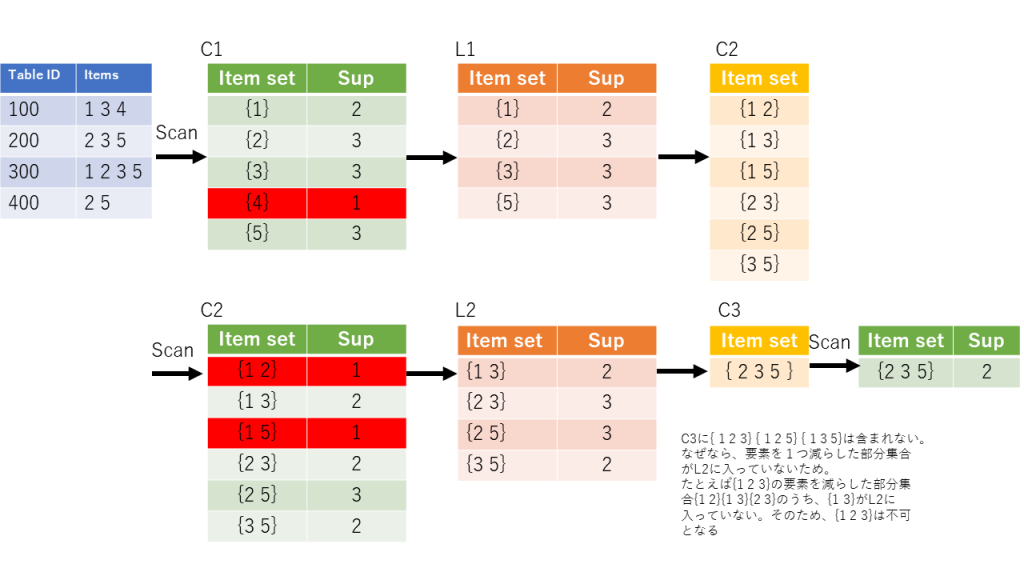
CNNでやっていることは実は単純です。CNNでは、入力画像にフィルターによる畳込み演算をし、それを特徴量マップとして次の層に渡します。この特徴マップづくりが特徴量を自動でつくる、と言われている部分でもあります。CNNは多層であるということを言いましたが、次の層でも、同様に畳込み演算を実施して、更に特徴量マップを作成します。そして次の層へ…ということを繰り返し実施するのです。何層にするかは自分で決めればいいのですが、大体2層くらいで落ち着かせる事が多くあります。
CNNの肝は特徴量マップ作りですが、これは言い換えればフィルター(畳み込みの重み)を学習により自動で求めることにあります。繰り返しフィルターの重みをを更新していく処理により精度を高めていきます。フィルターの更新にはバックプロパゲーション(誤差伝播)により更新していくのですが、こちらは後述します。
なお、畳込み処理ではReLU処理をする場合がほとんどです。ReLUとはmax( 0, x )というただのMAX処理で、畳こみ値がマイナスであれば0にする操作となります。
2.プーリング処理
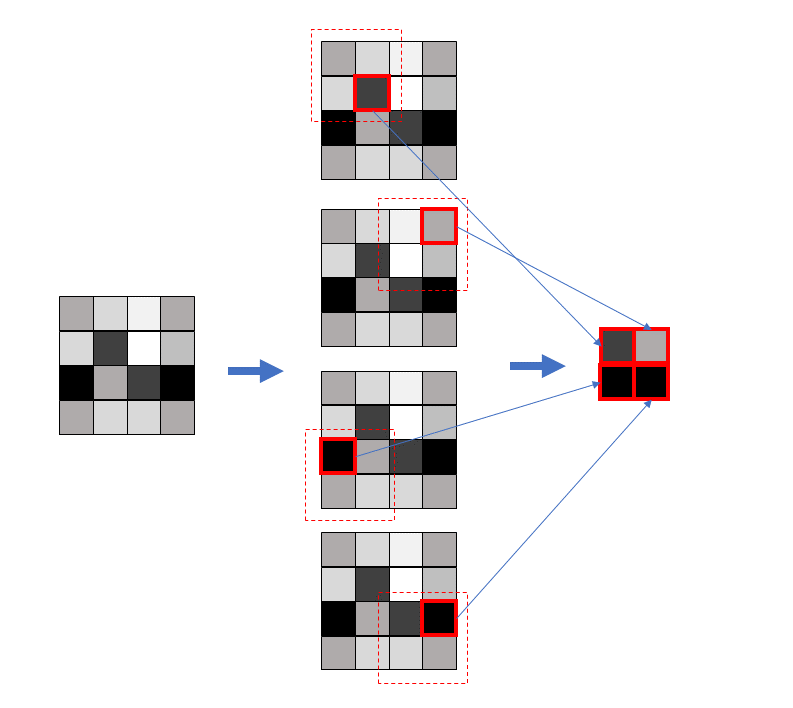
CNNではPoolingという作業(間引き)を行っています。Poolingは特徴量をマップを作った直後(あるいはReLU処理後)に実施します。
最も使われるPooling操作は畳み込み演算後の特徴マップから、ウィンドウの中で最大値だけをとるMaxPoolingです。Poolingを行う最大の目的は次元の削減にあります。またPooling操作は必須ではありません。事実、DCGANなど最近のDNNの一種では行っていません。ただ、伝統的な?CNNでは利用されています。また、至るところでも解説されているので覚えておくといいでしょう。
前段における注意事項
Note 1:入力画像がカラー画像の場合
入力画像がカラー画像のとき、つまりR,G,Bチャンネルが3つあるときですが、フィルターが3次元となります。例えばウィンドウサイズが3x3であれば、RGBを含め3x3x3のフィルターを用意します。このフィルターを適用して、特徴量マップの1つの要素ができます。
Note 2:何枚の特徴量マップを作ればいいのか
各層において、何枚の特徴量マップを作ればいいのかは、自由に決めます。64,128など、霧のいい数字を用いることが多いです。
NOTE 3: 何層作ればいいのか
2層の例が圧倒的に多いですが、こちらも経験的に決めているようです。
後段処理(Classification)
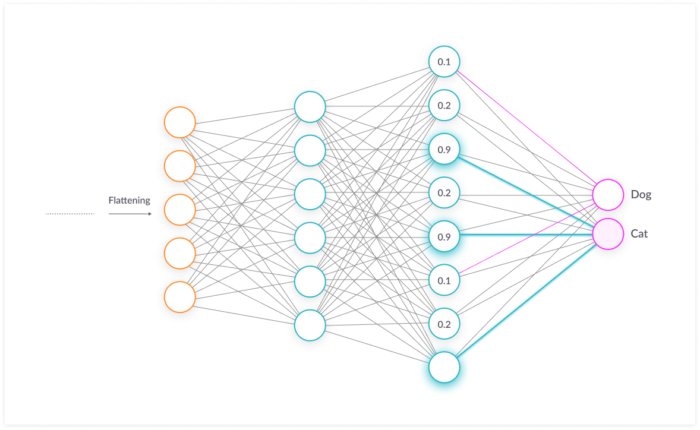
後段処理では、伝統的なニューラルネットワークを行います。例えば、最後に14x14の特徴量MAPが3つできたとします(14x14x3)。これを1次元にすると588次元です(Flattering処理)。これを用いて、普段のNNで使われるテクニックを使い、指定のクラスの次元まで落とし込むのです。SOFTMAXがよく使われています。この方法については、従来のNNそのものであるので割愛します。
Backward process
誤差伝搬はどのようにやるのでしょうか。後段処理についてはNNで今までと変わりません。前段の誤差伝搬処理について解説していきます。
誤差伝搬を行いますが、今までとの逆の操作をしていくことになります。前段処理は次のような流れでした。
画像 –> 特徴量マップ –> ReLU –> MaxPooling
本当は数回特徴量作成とPoolingをやりますが、ここでは簡単に一層で作成したと仮定し説明します。さて、逆操作では以下になります。
d Max Pooling –> d ReLU–>d Convolution(特徴マップ逆操作 )
d Max Pooling
Forward processでのMax Poolingは最大値だけを抽出し、次元を縮小する操作でした。Backward Processでは、次元縮小に利用したフィルターを用いて、後段から来た誤差をもとの大きさにもどしてやります。
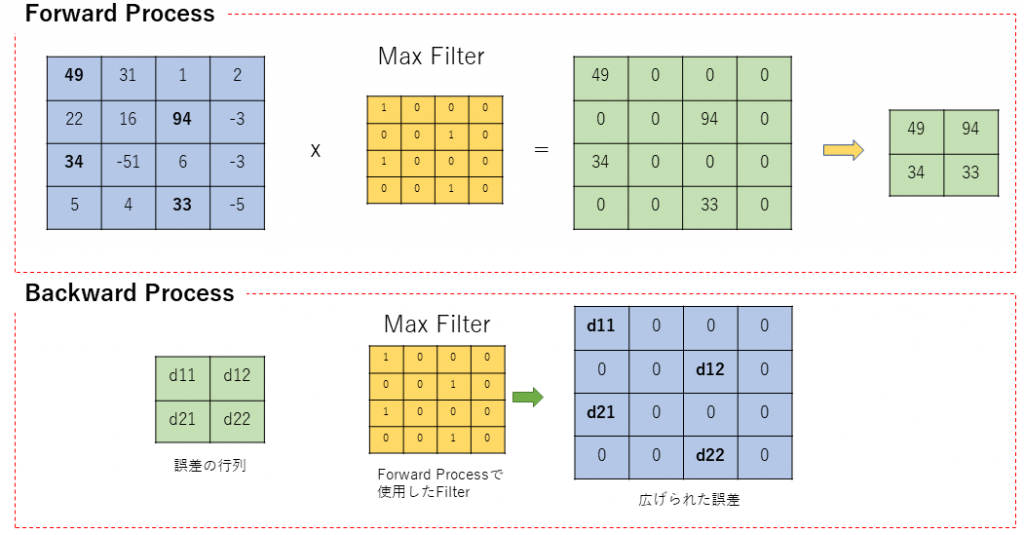
Backword processでは、このMAX Filterを使うので、前段で作ったMAX Filterは保持しておくことが必要です。
d ReLU
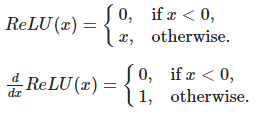
この操作を図示すると次のとおりです。単純に0より上であれば1にする操作となります。
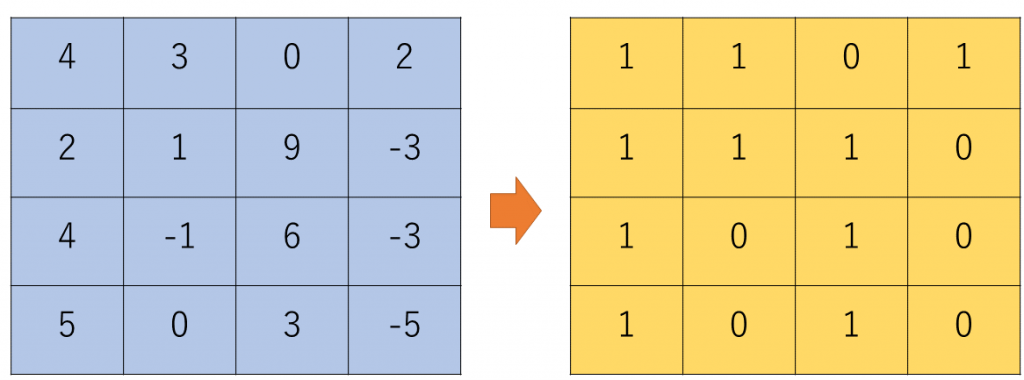
d Convolution
特徴量MAPの作成に利用したフィルターを使い、復元していきます。
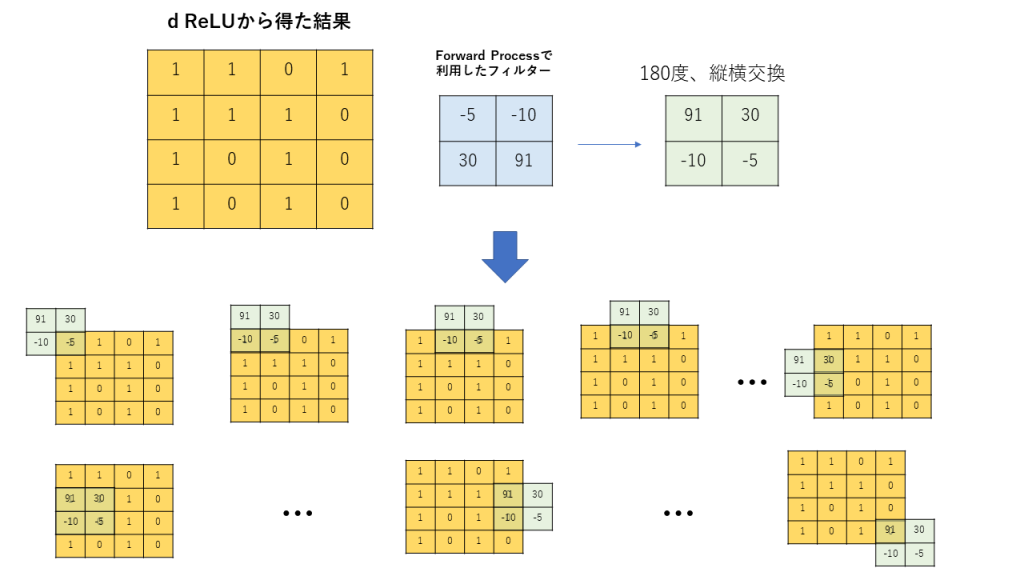
180度転置したものが伝搬で使われるのかについてはForward And Backpropagation in Convolutional Neural Network[1]に詳しく述べられていますので、参照ください。参考サイトは英語ですが、わかりやすい数式で述べられているので、興味ある人は読めるはずです。
参考文献
[1] medium.com/@2017csm1006/forward-and-backpropagation-in-convolutional-neural-network-4dfa96d7b37e